Parallel computations using RecursivelyEnumeratedSet and Map-Reduce¶
There is an efficient way to distribute computations on a set
\(S\) of objects defined by RecursivelyEnumeratedSet()
(see sage.sets.recursively_enumerated_set for more details)
over which one would like to perform the following kind of operations:
Compute the cardinality of a (very large) set defined recursively (through a call to
RecursivelyEnumeratedSet_forest)More generally, compute any kind of generating series over this set
Test a conjecture, e.g. find an element of \(S\) satisfying a specific property, or check that none does or that they all do
Count/list the elements of \(S\) that have a specific property
Apply any map/reduce kind of operation over the elements of \(S\)
AUTHORS:
Florent Hivert – code, documentation (2012–2016)
Jean Baptiste Priez – prototype, debugging help on MacOSX (2011-June, 2016)
Nathann Cohen – some documentation (2012)
Contents¶
How is this different from usual MapReduce?¶
This implementation is specific to RecursivelyEnumeratedSet_forest, and uses its
properties to do its job. Not only mapping and reducing but also
generating the elements of \(S\) is done on different processors.
How can I use all that stuff?¶
First, you need to set the environment variable SAGE_NUM_THREADS to the
desired number of parallel threads to be used:
sage: import os # not tested
sage: os.environ["SAGE_NUM_THREADS"] = '8' # not tested
>>> from sage.all import *
>>> import os # not tested
>>> os.environ["SAGE_NUM_THREADS"] = '8' # not tested
Second, you need the information necessary to describe a
RecursivelyEnumeratedSet_forest representing your set \(S\) (see
sage.sets.recursively_enumerated_set). Then, you need to provide a
“map” function as well as a “reduce” function. Here are some examples:
Counting the number of elements. In this situation, the map function can be set to
lambda x: 1, and the reduce function just adds the values together, i.e.lambda x, y: x + y.We count binary words of length \(\leq 16\):
sage: seeds = [[]] sage: succ = lambda l: [l + [0], l + [1]] if len(l) < 16 else [] sage: S = RecursivelyEnumeratedSet(seeds, succ, ....: structure='forest', enumeration='depth') sage: map_function = lambda x: 1 sage: reduce_function = lambda x, y: x + y sage: reduce_init = 0 sage: S.map_reduce(map_function, reduce_function, reduce_init) 131071
>>> from sage.all import * >>> seeds = [[]] >>> succ = lambda l: [l + [Integer(0)], l + [Integer(1)]] if len(l) < Integer(16) else [] >>> S = RecursivelyEnumeratedSet(seeds, succ, ... structure='forest', enumeration='depth') >>> map_function = lambda x: Integer(1) >>> reduce_function = lambda x, y: x + y >>> reduce_init = Integer(0) >>> S.map_reduce(map_function, reduce_function, reduce_init) 131071
This matches the number of binary words of length \(\leq 16\):
sage: factor(131071 + 1) 2^17
>>> from sage.all import * >>> factor(Integer(131071) + Integer(1)) 2^17
Note that the map and reduce functions here have the default values of the
sage.sets.recursively_enumerated_set.RecursivelyEnumeratedSet_forest.map_reduce()method so that the number of elements can be obtained more simply with:sage: S.map_reduce() 131071
>>> from sage.all import * >>> S.map_reduce() 131071
Instead of using
RecursivelyEnumeratedSet(), one can directly useRESetMapReduce, which gives finer control over the parallel execution (see Advanced use below):sage: from sage.parallel.map_reduce import RESetMapReduce sage: S = RESetMapReduce( ....: roots=[[]], ....: children=lambda l: [l + [0], l + [1]] if len(l) < 16 else [], ....: map_function=lambda x: 1, ....: reduce_function=lambda x, y: x + y, ....: reduce_init=0) sage: S.run() 131071
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMapReduce >>> S = RESetMapReduce( ... roots=[[]], ... children=lambda l: [l + [Integer(0)], l + [Integer(1)]] if len(l) < Integer(16) else [], ... map_function=lambda x: Integer(1), ... reduce_function=lambda x, y: x + y, ... reduce_init=Integer(0)) >>> S.run() 131071
Generating series. For this, take a Map function that associates a monomial to each element of \(S\), while the Reduce function is still equal to
lambda x, y: x + y.We compute the generating series for counting binary words of each length \(\leq 16\):
sage: S = RecursivelyEnumeratedSet( ....: [[]], lambda l: [l + [0], l + [1]] if len(l) < 16 else [], ....: structure='forest', enumeration='depth') sage: x = polygen(ZZ) sage: sp = S.map_reduce( ....: map_function=lambda z: x**len(z), ....: reduce_function=lambda x, y: x + y, ....: reduce_init=0) sage: sp 65536*x^16 + 32768*x^15 + 16384*x^14 + 8192*x^13 + 4096*x^12 + 2048*x^11 + 1024*x^10 + 512*x^9 + 256*x^8 + 128*x^7 + 64*x^6 + 32*x^5 + 16*x^4 + 8*x^3 + 4*x^2 + 2*x + 1
>>> from sage.all import * >>> S = RecursivelyEnumeratedSet( ... [[]], lambda l: [l + [Integer(0)], l + [Integer(1)]] if len(l) < Integer(16) else [], ... structure='forest', enumeration='depth') >>> x = polygen(ZZ) >>> sp = S.map_reduce( ... map_function=lambda z: x**len(z), ... reduce_function=lambda x, y: x + y, ... reduce_init=Integer(0)) >>> sp 65536*x^16 + 32768*x^15 + 16384*x^14 + 8192*x^13 + 4096*x^12 + 2048*x^11 + 1024*x^10 + 512*x^9 + 256*x^8 + 128*x^7 + 64*x^6 + 32*x^5 + 16*x^4 + 8*x^3 + 4*x^2 + 2*x + 1
This is of course \(\sum_{i=0}^{16} (2x)^i\):
sage: sp == sum((2*x)^i for i in range(17)) True
>>> from sage.all import * >>> sp == sum((Integer(2)*x)**i for i in range(Integer(17))) True
Here is another example where we count permutations of size \(\leq 8\) (here we use the default values):
sage: S = RecursivelyEnumeratedSet( ....: [[]], ....: lambda l: ([l[:i] + [len(l)] + l[i:] ....: for i in range(len(l) + 1)] if len(l) < 8 else []), ....: structure='forest', ....: enumeration='depth') sage: x = polygen(ZZ) sage: sp = S.map_reduce(lambda z: x**len(z)); sp 40320*x^8 + 5040*x^7 + 720*x^6 + 120*x^5 + 24*x^4 + 6*x^3 + 2*x^2 + x + 1
>>> from sage.all import * >>> S = RecursivelyEnumeratedSet( ... [[]], ... lambda l: ([l[:i] + [len(l)] + l[i:] ... for i in range(len(l) + Integer(1))] if len(l) < Integer(8) else []), ... structure='forest', ... enumeration='depth') >>> x = polygen(ZZ) >>> sp = S.map_reduce(lambda z: x**len(z)); sp 40320*x^8 + 5040*x^7 + 720*x^6 + 120*x^5 + 24*x^4 + 6*x^3 + 2*x^2 + x + 1
This is of course \(\sum_{i=0}^{8} i! x^i\):
sage: sp == sum(factorial(i)*x^i for i in range(9)) True
>>> from sage.all import * >>> sp == sum(factorial(i)*x**i for i in range(Integer(9))) True
Post Processing. We now demonstrate the use of
post_process. We generate the permutation as previously, but we only perform the map/reduce computation on those of evenlen. Of course we get the even part of the previous generating series:sage: S = RecursivelyEnumeratedSet( ....: [[]], ....: lambda l: ([l[:i] + [len(l) + 1] + l[i:] ....: for i in range(len(l) + 1)] if len(l) < 8 else []), ....: post_process=lambda l: l if len(l) % 2 == 0 else None, ....: structure='forest', ....: enumeration='depth') sage: sp = S.map_reduce(lambda z: x**len(z)); sp 40320*x^8 + 720*x^6 + 24*x^4 + 2*x^2 + 1
>>> from sage.all import * >>> S = RecursivelyEnumeratedSet( ... [[]], ... lambda l: ([l[:i] + [len(l) + Integer(1)] + l[i:] ... for i in range(len(l) + Integer(1))] if len(l) < Integer(8) else []), ... post_process=lambda l: l if len(l) % Integer(2) == Integer(0) else None, ... structure='forest', ... enumeration='depth') >>> sp = S.map_reduce(lambda z: x**len(z)); sp 40320*x^8 + 720*x^6 + 24*x^4 + 2*x^2 + 1
This is also useful for example to call a constructor on the generated elements:
sage: S = RecursivelyEnumeratedSet( ....: [[]], ....: lambda l: ([l[:i] + [len(l) + 1] + l[i:] ....: for i in range(len(l) + 1)] if len(l) < 5 else []), ....: post_process=lambda l: Permutation(l) if len(l) == 5 else None, ....: structure='forest', ....: enumeration='depth') sage: x = polygen(ZZ) sage: sp = S.map_reduce(lambda z: x**z.number_of_inversions()); sp x^10 + 4*x^9 + 9*x^8 + 15*x^7 + 20*x^6 + 22*x^5 + 20*x^4 + 15*x^3 + 9*x^2 + 4*x + 1
>>> from sage.all import * >>> S = RecursivelyEnumeratedSet( ... [[]], ... lambda l: ([l[:i] + [len(l) + Integer(1)] + l[i:] ... for i in range(len(l) + Integer(1))] if len(l) < Integer(5) else []), ... post_process=lambda l: Permutation(l) if len(l) == Integer(5) else None, ... structure='forest', ... enumeration='depth') >>> x = polygen(ZZ) >>> sp = S.map_reduce(lambda z: x**z.number_of_inversions()); sp x^10 + 4*x^9 + 9*x^8 + 15*x^7 + 20*x^6 + 22*x^5 + 20*x^4 + 15*x^3 + 9*x^2 + 4*x + 1
We get here a polynomial which is the \(q\)-factorial (in the variable \(x\)) of \(5\), that is, \(\prod_{i=1}^{5} \frac{1-x^i}{1-x}\):
sage: x = polygen(ZZ) sage: prod((1-x^i)//(1-x) for i in range(1, 6)) x^10 + 4*x^9 + 9*x^8 + 15*x^7 + 20*x^6 + 22*x^5 + 20*x^4 + 15*x^3 + 9*x^2 + 4*x + 1
>>> from sage.all import * >>> x = polygen(ZZ) >>> prod((Integer(1)-x**i)//(Integer(1)-x) for i in range(Integer(1), Integer(6))) x^10 + 4*x^9 + 9*x^8 + 15*x^7 + 20*x^6 + 22*x^5 + 20*x^4 + 15*x^3 + 9*x^2 + 4*x + 1
Compare:
sage: from sage.combinat.q_analogues import q_factorial # needs sage.combinat sage: q_factorial(5) # needs sage.combinat q^10 + 4*q^9 + 9*q^8 + 15*q^7 + 20*q^6 + 22*q^5 + 20*q^4 + 15*q^3 + 9*q^2 + 4*q + 1
>>> from sage.all import * >>> from sage.combinat.q_analogues import q_factorial # needs sage.combinat >>> q_factorial(Integer(5)) # needs sage.combinat q^10 + 4*q^9 + 9*q^8 + 15*q^7 + 20*q^6 + 22*q^5 + 20*q^4 + 15*q^3 + 9*q^2 + 4*q + 1
Listing the objects. One can also compute the list of objects in a
RecursivelyEnumeratedSet_forest>usingRESetMapReduce. As an example, we compute the set of numbers between 1 and 63, generated by their binary expansion:sage: S = RecursivelyEnumeratedSet( ....: [1], ....: lambda l: [(l<<1)|0, (l<<1)|1] if l < 1<<5 else [], ....: structure='forest', ....: enumeration='depth')
>>> from sage.all import * >>> S = RecursivelyEnumeratedSet( ... [Integer(1)], ... lambda l: [(l<<Integer(1))|Integer(0), (l<<Integer(1))|Integer(1)] if l < Integer(1)<<Integer(5) else [], ... structure='forest', ... enumeration='depth')
Here is the list computed without
RESetMapReduce:sage: serial = list(S) sage: serial [1, 2, 4, 8, 16, 32, 33, 17, 34, 35, 9, 18, 36, 37, 19, 38, 39, 5, 10, 20, 40, 41, 21, 42, 43, 11, 22, 44, 45, 23, 46, 47, 3, 6, 12, 24, 48, 49, 25, 50, 51, 13, 26, 52, 53, 27, 54, 55, 7, 14, 28, 56, 57, 29, 58, 59, 15, 30, 60, 61, 31, 62, 63]
>>> from sage.all import * >>> serial = list(S) >>> serial [1, 2, 4, 8, 16, 32, 33, 17, 34, 35, 9, 18, 36, 37, 19, 38, 39, 5, 10, 20, 40, 41, 21, 42, 43, 11, 22, 44, 45, 23, 46, 47, 3, 6, 12, 24, 48, 49, 25, 50, 51, 13, 26, 52, 53, 27, 54, 55, 7, 14, 28, 56, 57, 29, 58, 59, 15, 30, 60, 61, 31, 62, 63]
Here is how to perform the parallel computation. The order of the lists depends on the synchronisation of the various computation processes and therefore should be considered as random:
sage: parall = S.map_reduce(lambda x: [x], lambda x, y: x + y, []) sage: parall # random [1, 3, 7, 15, 31, 63, 62, 30, 61, 60, 14, 29, 59, 58, 28, 57, 56, 6, 13, 27, 55, 54, 26, 53, 52, 12, 25, 51, 50, 24, 49, 48, 2, 5, 11, 23, 47, 46, 22, 45, 44, 10, 21, 43, 42, 20, 41, 40, 4, 9, 19, 39, 38, 18, 37, 36, 8, 17, 35, 34, 16, 33, 32] sage: sorted(serial) == sorted(parall) True
>>> from sage.all import * >>> parall = S.map_reduce(lambda x: [x], lambda x, y: x + y, []) >>> parall # random [1, 3, 7, 15, 31, 63, 62, 30, 61, 60, 14, 29, 59, 58, 28, 57, 56, 6, 13, 27, 55, 54, 26, 53, 52, 12, 25, 51, 50, 24, 49, 48, 2, 5, 11, 23, 47, 46, 22, 45, 44, 10, 21, 43, 42, 20, 41, 40, 4, 9, 19, 39, 38, 18, 37, 36, 8, 17, 35, 34, 16, 33, 32] >>> sorted(serial) == sorted(parall) True
Advanced use¶
Fine control over the execution of a map/reduce computation is achieved
via parameters passed to the RESetMapReduce.run() method.
The following three parameters can be used:
max_proc– (integer, default:None) if given, the maximum number of worker processors to use. The actual number is also bounded by the value of the environment variableSAGE_NUM_THREADS(the number of cores by default).timeout– a timeout on the computation (default:None)reduce_locally– whether the workers should reduce locally their work or sends results to the master as soon as possible. SeeRESetMapReduceWorkerfor details.
Here is an example or how to deal with timeout:
sage: from sage.parallel.map_reduce import (RESetMPExample, AbortError)
sage: EX = RESetMPExample(maxl=100)
sage: try:
....: res = EX.run(timeout=float(0.01))
....: except AbortError:
....: print("Computation timeout")
....: else:
....: print("Computation normally finished")
....: res
Computation timeout
>>> from sage.all import *
>>> from sage.parallel.map_reduce import (RESetMPExample, AbortError)
>>> EX = RESetMPExample(maxl=Integer(100))
>>> try:
... res = EX.run(timeout=float(RealNumber('0.01')))
... except AbortError:
... print("Computation timeout")
... else:
... print("Computation normally finished")
... res
Computation timeout
The following should not timeout even on a very slow machine:
sage: EX = RESetMPExample(maxl=8)
sage: try:
....: res = EX.run(timeout=60)
....: except AbortError:
....: print("Computation Timeout")
....: else:
....: print("Computation normally finished")
....: res
Computation normally finished
40320*x^8 + 5040*x^7 + 720*x^6 + 120*x^5 + 24*x^4 + 6*x^3 + 2*x^2 + x + 1
>>> from sage.all import *
>>> EX = RESetMPExample(maxl=Integer(8))
>>> try:
... res = EX.run(timeout=Integer(60))
... except AbortError:
... print("Computation Timeout")
... else:
... print("Computation normally finished")
... res
Computation normally finished
40320*x^8 + 5040*x^7 + 720*x^6 + 120*x^5 + 24*x^4 + 6*x^3 + 2*x^2 + x + 1
As for reduce_locally, one should not see any difference, except for speed
during normal usage. Most of the time one should leave it set to True,
unless one sets up a mechanism to consume the partial results as soon as they
arrive. See RESetParallelIterator and in particular the __iter__
method for a example of consumer use.
Profiling¶
It is possible to profile a map/reduce computation. First we create a
RESetMapReduce object:
sage: from sage.parallel.map_reduce import RESetMapReduce
sage: S = RESetMapReduce(
....: roots=[[]],
....: children=lambda l: [l + [0], l + [1]] if len(l) < 16 else [],
....: map_function=lambda x: 1,
....: reduce_function=lambda x, y: x + y,
....: reduce_init=0)
>>> from sage.all import *
>>> from sage.parallel.map_reduce import RESetMapReduce
>>> S = RESetMapReduce(
... roots=[[]],
... children=lambda l: [l + [Integer(0)], l + [Integer(1)]] if len(l) < Integer(16) else [],
... map_function=lambda x: Integer(1),
... reduce_function=lambda x, y: x + y,
... reduce_init=Integer(0))
The profiling is activated by the profile parameter. The value provided
should be a prefix (including a possible directory) for the profile dump:
sage: import tempfile
sage: d = tempfile.TemporaryDirectory(prefix='RESetMR_profile')
sage: res = S.run(profile=d.name) # random
[RESetMapReduceWorker-1:58] (20:00:41.444) Profiling in
/home/user/.sage/temp/.../32414/RESetMR_profilewRCRAx/profcomp1
...
[RESetMapReduceWorker-1:57] (20:00:41.444) Profiling in
/home/user/.sage/temp/.../32414/RESetMR_profilewRCRAx/profcomp0
...
sage: res
131071
>>> from sage.all import *
>>> import tempfile
>>> d = tempfile.TemporaryDirectory(prefix='RESetMR_profile')
>>> res = S.run(profile=d.name) # random
[RESetMapReduceWorker-1:58] (20:00:41.444) Profiling in
/home/user/.sage/temp/.../32414/RESetMR_profilewRCRAx/profcomp1
...
[RESetMapReduceWorker-1:57] (20:00:41.444) Profiling in
/home/user/.sage/temp/.../32414/RESetMR_profilewRCRAx/profcomp0
...
>>> res
131071
In this example, the profiles have been dumped in files such as
profcomp0. One can then load and print them as follows. See
cProfile.Profile for more details:
sage: import cProfile, pstats
sage: st = pstats.Stats(d.name+'0')
sage: st.strip_dirs().sort_stats('cumulative').print_stats() # random
...
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.023 0.023 0.432 0.432 map_reduce.py:1211(run_myself)
11968 0.151 0.000 0.223 0.000 map_reduce.py:1292(walk_branch_locally)
...
<pstats.Stats instance at 0x7fedea40c6c8>
>>> from sage.all import *
>>> import cProfile, pstats
>>> st = pstats.Stats(d.name+'0')
>>> st.strip_dirs().sort_stats('cumulative').print_stats() # random
...
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.023 0.023 0.432 0.432 map_reduce.py:1211(run_myself)
11968 0.151 0.000 0.223 0.000 map_reduce.py:1292(walk_branch_locally)
...
<pstats.Stats instance at 0x7fedea40c6c8>
Like a good neighbor we clean up our temporary directory as soon as possible:
sage: d.cleanup()
>>> from sage.all import *
>>> d.cleanup()
See also
The Python Profilers for more detail on profiling in python.
Logging¶
The computation progress is logged through a logging.Logger in
sage.parallel.map_reduce.logger together with logging.StreamHandler
and a logging.Formatter. They are currently configured to print
warning messages to the console.
See also
Logging facility for Python for more detail on logging and log system configuration.
Note
Calls to logger which involve printing the node are commented out in the code, because the printing (to a string) of the node can be very time consuming depending on the node and it happens before the decision whether the logger should record the string or drop it.
How does it work ?¶
The scheduling algorithm we use here is any adaptation of Wikipedia article Work_stealing:
In a work stealing scheduler, each processor in a computer system has a queue of work items (computational tasks, threads) to perform. […]. Each work items are initially put on the queue of the processor executing the work item. When a processor runs out of work, it looks at the queues of other processors and “steals” their work items. In effect, work stealing distributes the scheduling work over idle processors, and as long as all processors have work to do, no scheduling overhead occurs.
For communication we use Python’s basic multiprocessing module. We
first describe the different actors and communication tools used by the
system. The work is done under the coordination of a master object (an
instance of RESetMapReduce) by a bunch of worker objects
(instances of RESetMapReduceWorker).
Each running map reduce instance works on a RecursivelyEnumeratedSet_forest> called here \(C\) and is
coordinated by a RESetMapReduce object called the master. The
master is in charge of launching the work, gathering the results and cleaning
up at the end of the computation. It doesn’t perform any computation
associated to the generation of the element \(C\) nor the computation of the
mapped function. It however occasionally perform a reduce, but most reducing
is by default done by the workers. Also thanks to the work-stealing algorithm,
the master is only involved in detecting the termination of the computation
but all the load balancing is done at the level of the workers.
Workers are instances of RESetMapReduceWorker. They are responsible
for doing the actual computations: element generation, mapping and reducing.
They are also responsible for the load balancing thanks to work-stealing.
Here is a description of the attributes of the master relevant to the map-reduce protocol:
_results– aSimpleQueuewhere the master gathers the results sent by the workers_active_tasks– aSemaphorerecording the number of active tasks; the work is complete when it reaches 0_done– aLockwhich ensures that shutdown is done only once_aborted– aValue()storing a sharedctypes.c_boolwhich isTrueif the computation was aborted before all workers ran out of work_workers– list ofRESetMapReduceWorkerobjects Each worker is identified by its position in this list
Each worker is a process (RESetMapReduceWorker inherits from
Process) which contains:
worker._iproc– the identifier of the worker that is its position in the master’s list of workersworker._todo– acollections.dequestoring of nodes of the worker. It is used as a stack by the worker. Thiefs steal from the bottom of this queue.worker._request– aSimpleQueuestoring steal request submitted toworkerworker._read_task,worker._write_task– aPipeused to transfer node during stealworker._thief– aThreadwhich is in charge of stealing fromworker._todo
Here is a schematic of the architecture:
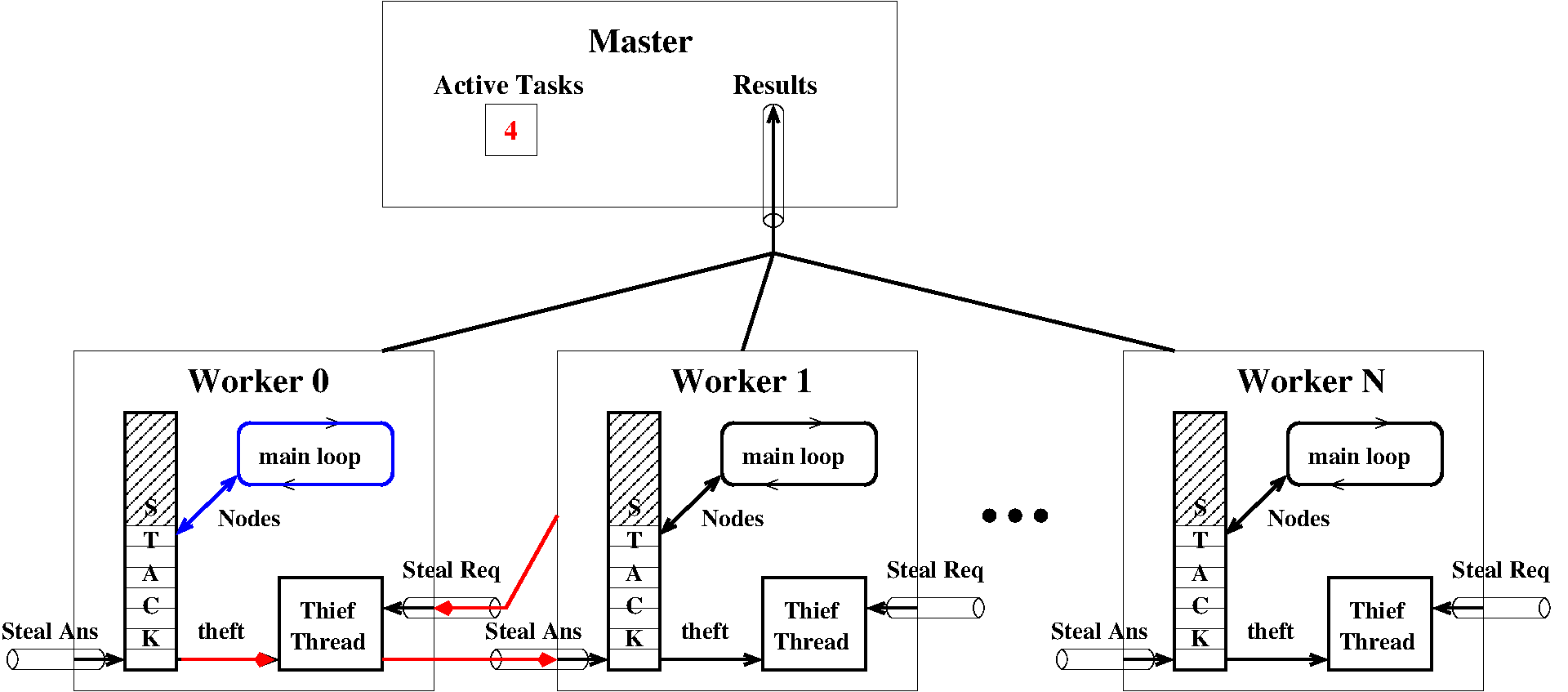
How thefts are performed¶
During normal time, that is, when all workers are active, a worker W is
iterating though a loop inside
RESetMapReduceWorker.walk_branch_locally(). Work nodes are taken from
and new nodes W._todo are appended to W._todo. When a worker W
runs out of work, that is, when worker._todo is empty, it tries to steal
some work (i.e., a node) from another worker. This is performed in the
RESetMapReduceWorker.steal() method.
From the point of view of W, here is what happens:
Wsignals to the master that it is idle:master._signal_task_done;Wchooses a victimVat random;Wsends a request toV: it puts its identifier intoV._request;Wtries to read a node fromW._read_task. Then three things may happen:a proper node is read. Then the theft was a success and
Wstarts working locally on the received node.Noneis received. This means thatVwas idle. ThenWtries another victim.AbortErroris received. This means either that the computation was aborted or that it simply succeeded and that no more work is required byW. Therefore anAbortErrorexception is raised leadingWto shutdown.
We now describe the protocol on the victim’s side. Each worker process contains
a Thread which we call T for thief which acts like some kind of
Troyan horse during theft. It is normally blocked waiting for a steal request.
From the point of view of V and T, here is what happens:
during normal time,
Tis blocked waiting onV._request;upon steal request,
Twakes up receiving the identification ofW;Tsignals to the master that a new task is starting bymaster._signal_task_start;Two things may happen depending if the queue
V._todois empty or not. Remark that due to the GIL, there is no parallel execution between the victimVand its thief threadT.If
V._todois empty, thenNoneis answered onW._write_task. The task is immediately signaled to end the master throughmaster._signal_task_done.Otherwise, a node is removed from the bottom of
V._todo. The node is sent toWonW._write_task. The task will be ended byW, that is, when finished working on the subtree rooted at the node,Wwill callmaster._signal_task_done.
The end of the computation¶
To detect when a computation is finished, a synchronized integer is kept which
counts the number of active tasks. This is essentially a semaphore but
semaphores are broken on Darwin OSes so we ship two implementations depending
on the OS (see ActiveTaskCounter and ActiveTaskCounterDarwin
and the note below).
When a worker finishes working on a task, it calls
master._signal_task_done. This decreases the task counter
master._active_tasks. When it reaches 0, it means that there are no more
nodes: the work is completed. The worker executes master._shutdown
which sends AbortError to all worker._request and
worker._write_task queues. Each worker or thief thread receiving such
a message raises the corresponding exception, therefore stopping its work. A
lock called master._done ensures that shutdown is only done once.
Finally, it is also possible to interrupt the computation before its ends,
by calling master.abort(). This is achieved by setting
master._active_tasks to 0 and calling master._shutdown.
Warning
The macOS Semaphore bug
Darwin OSes do not correctly implement POSIX’s semaphore semantic. Indeed, on these systems, acquire may fail and return False not only when the semaphore is equal to zero but also because someone else is trying to acquire at the same time. This makes using Semaphores impossible on macOS so that on these systems we use a synchronized integer instead.
Are there examples of classes?¶
Yes! Here they are:
RESetMPExample– a simple basic exampleRESetParallelIterator– a more advanced example using non standard communication configuration
Tests¶
Generating series for the sum of strictly decreasing lists of integers smaller than 15:
sage: y = polygen(ZZ, 'y')
sage: R = RESetMapReduce(
....: roots=[([], 0, 0)] + [([i], i, i) for i in range(1, 15)],
....: children=lambda list_sum_last:
....: [(list_sum_last[0] + [i], list_sum_last[1] + i, i)
....: for i in range(1, list_sum_last[2])],
....: map_function=lambda li_sum_dummy: y**li_sum_dummy[1])
sage: sg = R.run()
sage: sg == prod((1 + y**i) for i in range(1, 15))
True
>>> from sage.all import *
>>> y = polygen(ZZ, 'y')
>>> R = RESetMapReduce(
... roots=[([], Integer(0), Integer(0))] + [([i], i, i) for i in range(Integer(1), Integer(15))],
... children=lambda list_sum_last:
... [(list_sum_last[Integer(0)] + [i], list_sum_last[Integer(1)] + i, i)
... for i in range(Integer(1), list_sum_last[Integer(2)])],
... map_function=lambda li_sum_dummy: y**li_sum_dummy[Integer(1)])
>>> sg = R.run()
>>> sg == prod((Integer(1) + y**i) for i in range(Integer(1), Integer(15)))
True
Classes and methods¶
- exception sage.parallel.map_reduce.AbortError[source]¶
Bases:
ExceptionException for aborting parallel computations.
This is used both as exception or as abort message.
- sage.parallel.map_reduce.ActiveTaskCounter[source]¶
alias of
ActiveTaskCounterPosix
- class sage.parallel.map_reduce.ActiveTaskCounterDarwin(task_number)[source]¶
Bases:
objectHandling the number of active tasks.
A class for handling the number of active tasks in a distributed computation process. This is essentially a semaphore, but Darwin OSes do not correctly implement POSIX’s semaphore semantic. So we use a shared integer with a lock.
- abort()[source]¶
Set the task counter to zero.
EXAMPLES:
sage: from sage.parallel.map_reduce import ActiveTaskCounterDarwin as ATC sage: c = ATC(4); c ActiveTaskCounter(value=4) sage: c.abort() sage: c ActiveTaskCounter(value=0)
>>> from sage.all import * >>> from sage.parallel.map_reduce import ActiveTaskCounterDarwin as ATC >>> c = ATC(Integer(4)); c ActiveTaskCounter(value=4) >>> c.abort() >>> c ActiveTaskCounter(value=0)
- task_done()[source]¶
Decrement the task counter by one.
OUTPUT:
Calling
task_done()decrements the counter and returns its new value.EXAMPLES:
sage: from sage.parallel.map_reduce import ActiveTaskCounterDarwin as ATC sage: c = ATC(4); c ActiveTaskCounter(value=4) sage: c.task_done() 3 sage: c ActiveTaskCounter(value=3) sage: c = ATC(0) sage: c.task_done() -1
>>> from sage.all import * >>> from sage.parallel.map_reduce import ActiveTaskCounterDarwin as ATC >>> c = ATC(Integer(4)); c ActiveTaskCounter(value=4) >>> c.task_done() 3 >>> c ActiveTaskCounter(value=3) >>> c = ATC(Integer(0)) >>> c.task_done() -1
- task_start()[source]¶
Increment the task counter by one.
OUTPUT:
Calling
task_start()on a zero or negative counter returns 0, otherwise increment the counter and returns its value after the incrementation.EXAMPLES:
sage: from sage.parallel.map_reduce import ActiveTaskCounterDarwin as ATC sage: c = ATC(4); c ActiveTaskCounter(value=4) sage: c.task_start() 5 sage: c ActiveTaskCounter(value=5)
>>> from sage.all import * >>> from sage.parallel.map_reduce import ActiveTaskCounterDarwin as ATC >>> c = ATC(Integer(4)); c ActiveTaskCounter(value=4) >>> c.task_start() 5 >>> c ActiveTaskCounter(value=5)
Calling
task_start()on a zero counter does nothing:sage: c = ATC(0) sage: c.task_start() 0 sage: c ActiveTaskCounter(value=0)
>>> from sage.all import * >>> c = ATC(Integer(0)) >>> c.task_start() 0 >>> c ActiveTaskCounter(value=0)
- class sage.parallel.map_reduce.ActiveTaskCounterPosix(task_number)[source]¶
Bases:
objectHandling the number of active tasks.
A class for handling the number of active tasks in a distributed computation process. This is the standard implementation on POSIX compliant OSes. We essentially wrap a semaphore.
Note
A legitimate question is whether there is a need in keeping the two implementations. I ran the following experiment on my machine:
S = RecursivelyEnumeratedSet( [[]], lambda l: ([l[:i] + [len(l)] + l[i:] for i in range(len(l) + 1)] if len(l) < NNN else []), structure='forest', enumeration='depth') %time sp = S.map_reduce(lambda z: x**len(z)); sp
For NNN = 10, averaging a dozen of runs, I got:
Posix compliant implementation: 17.04 s
Darwin implementation: 18.26 s
So there is a non negligible overhead. It will probably be worth it if we try to cythonize the code. So I’m keeping both implementations.
- abort()[source]¶
Set the task counter to zero.
EXAMPLES:
sage: from sage.parallel.map_reduce import ActiveTaskCounter as ATC sage: c = ATC(4); c ActiveTaskCounter(value=4) sage: c.abort() sage: c ActiveTaskCounter(value=0)
>>> from sage.all import * >>> from sage.parallel.map_reduce import ActiveTaskCounter as ATC >>> c = ATC(Integer(4)); c ActiveTaskCounter(value=4) >>> c.abort() >>> c ActiveTaskCounter(value=0)
- task_done()[source]¶
Decrement the task counter by one.
OUTPUT:
Calling
task_done()decrements the counter and returns its new value.EXAMPLES:
sage: from sage.parallel.map_reduce import ActiveTaskCounter as ATC sage: c = ATC(4); c ActiveTaskCounter(value=4) sage: c.task_done() 3 sage: c ActiveTaskCounter(value=3) sage: c = ATC(0) sage: c.task_done() -1
>>> from sage.all import * >>> from sage.parallel.map_reduce import ActiveTaskCounter as ATC >>> c = ATC(Integer(4)); c ActiveTaskCounter(value=4) >>> c.task_done() 3 >>> c ActiveTaskCounter(value=3) >>> c = ATC(Integer(0)) >>> c.task_done() -1
- task_start()[source]¶
Increment the task counter by one.
OUTPUT:
Calling
task_start()on a zero or negative counter returns 0, otherwise increment the counter and returns its value after the incrementation.EXAMPLES:
sage: from sage.parallel.map_reduce import ActiveTaskCounterDarwin as ATC sage: c = ATC(4); c ActiveTaskCounter(value=4) sage: c.task_start() 5 sage: c ActiveTaskCounter(value=5)
>>> from sage.all import * >>> from sage.parallel.map_reduce import ActiveTaskCounterDarwin as ATC >>> c = ATC(Integer(4)); c ActiveTaskCounter(value=4) >>> c.task_start() 5 >>> c ActiveTaskCounter(value=5)
Calling
task_start()on a zero counter does nothing:sage: c = ATC(0) sage: c.task_start() 0 sage: c ActiveTaskCounter(value=0)
>>> from sage.all import * >>> c = ATC(Integer(0)) >>> c.task_start() 0 >>> c ActiveTaskCounter(value=0)
- class sage.parallel.map_reduce.RESetMPExample(maxl=9)[source]¶
Bases:
RESetMapReduceAn example of map reduce class.
INPUT:
maxl– the maximum size of permutations generated (default: \(9\))
This computes the generating series of permutations counted by their size up to size
maxl.EXAMPLES:
sage: from sage.parallel.map_reduce import RESetMPExample sage: EX = RESetMPExample() sage: EX.run() 362880*x^9 + 40320*x^8 + 5040*x^7 + 720*x^6 + 120*x^5 + 24*x^4 + 6*x^3 + 2*x^2 + x + 1
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMPExample >>> EX = RESetMPExample() >>> EX.run() 362880*x^9 + 40320*x^8 + 5040*x^7 + 720*x^6 + 120*x^5 + 24*x^4 + 6*x^3 + 2*x^2 + x + 1
See also
This is an example of
RESetMapReduce- children(l)[source]¶
Return the children of the permutation \(l\).
INPUT:
l– list containing a permutation
OUTPUT:
The lists with
len(l)inserted at all possible positions intol.EXAMPLES:
sage: from sage.parallel.map_reduce import RESetMPExample sage: RESetMPExample().children([1,0]) [[2, 1, 0], [1, 2, 0], [1, 0, 2]]
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMPExample >>> RESetMPExample().children([Integer(1),Integer(0)]) [[2, 1, 0], [1, 2, 0], [1, 0, 2]]
- map_function(l)[source]¶
The monomial associated to the permutation \(l\).
INPUT:
l– list containing a permutation
OUTPUT:
The monomial
x^len(l).EXAMPLES:
sage: from sage.parallel.map_reduce import RESetMPExample sage: RESetMPExample().map_function([1,0]) x^2
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMPExample >>> RESetMPExample().map_function([Integer(1),Integer(0)]) x^2
- class sage.parallel.map_reduce.RESetMapReduce(roots=None, children=None, post_process=None, map_function=None, reduce_function=None, reduce_init=None, forest=None)[source]¶
Bases:
objectMap-Reduce on recursively enumerated sets.
INPUT:
Description of the set:
either
forest=f– wherefis aRecursivelyEnumeratedSet_forest>or a triple
roots, children, post_processas followsroots=r– the root of the enumerationchildren=c– a function iterating through children nodes, given a parent nodepost_process=p– a post-processing function
The option
post_processallows for customizing the nodes that are actually produced. Furthermore, ifpost_process(x)returnsNone, thenxwon’t be output at all.Description of the map/reduce operation:
map_function=f– (default:None)reduce_function=red– (default:None)reduce_init=init– (default:None)
See also
the Map/Reduce modulefor details and examples.- abort()[source]¶
Abort the current parallel computation.
EXAMPLES:
sage: from sage.parallel.map_reduce import RESetParallelIterator sage: S = RESetParallelIterator([[]], ....: lambda l: [l + [0], l + [1]] if len(l) < 17 else []) sage: it = iter(S) sage: next(it) # random [] sage: S.abort() sage: hasattr(S, 'work_queue') False
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetParallelIterator >>> S = RESetParallelIterator([[]], ... lambda l: [l + [Integer(0)], l + [Integer(1)]] if len(l) < Integer(17) else []) >>> it = iter(S) >>> next(it) # random [] >>> S.abort() >>> hasattr(S, 'work_queue') False
Cleanup:
sage: S.finish()
>>> from sage.all import * >>> S.finish()
- finish()[source]¶
Destroy the workers and all the communication objects.
Communication statistics are gathered before destroying the workers.
See also
- get_results(timeout=None)[source]¶
Get the results from the queue.
OUTPUT:
The reduction of the results of all the workers, that is, the result of the map/reduce computation.
EXAMPLES:
sage: from sage.parallel.map_reduce import RESetMapReduce sage: S = RESetMapReduce() sage: S.setup_workers(2) sage: for v in [1, 2, None, 3, None]: S._results.put(v) sage: S.get_results() 6
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMapReduce >>> S = RESetMapReduce() >>> S.setup_workers(Integer(2)) >>> for v in [Integer(1), Integer(2), None, Integer(3), None]: S._results.put(v) >>> S.get_results() 6
Cleanup:
sage: del S._results, S._active_tasks, S._done, S._workers
>>> from sage.all import * >>> del S._results, S._active_tasks, S._done, S._workers
- map_function(o)[source]¶
Return the function mapped by
self.INPUT:
o– a node
OUTPUT: by default
1Note
This should be overloaded in applications.
EXAMPLES:
sage: from sage.parallel.map_reduce import RESetMapReduce sage: S = RESetMapReduce() sage: S.map_function(7) 1 sage: S = RESetMapReduce(map_function = lambda x: 3*x + 5) sage: S.map_function(7) 26
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMapReduce >>> S = RESetMapReduce() >>> S.map_function(Integer(7)) 1 >>> S = RESetMapReduce(map_function = lambda x: Integer(3)*x + Integer(5)) >>> S.map_function(Integer(7)) 26
- post_process(a)[source]¶
Return the image of
aunder the post-processing function forself.INPUT:
a– a node
With the default post-processing function, which is the identity function, this returns
aitself.Note
This should be overloaded in applications.
EXAMPLES:
sage: from sage.parallel.map_reduce import RESetMapReduce sage: S = RESetMapReduce() sage: S.post_process(4) 4 sage: S = RESetMapReduce(post_process=lambda x: x*x) sage: S.post_process(4) 16
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMapReduce >>> S = RESetMapReduce() >>> S.post_process(Integer(4)) 4 >>> S = RESetMapReduce(post_process=lambda x: x*x) >>> S.post_process(Integer(4)) 16
- print_communication_statistics(blocksize=16)[source]¶
Print the communication statistics in a nice way.
EXAMPLES:
sage: from sage.parallel.map_reduce import RESetMPExample sage: S = RESetMPExample(maxl=6) sage: S.run() 720*x^6 + 120*x^5 + 24*x^4 + 6*x^3 + 2*x^2 + x + 1 sage: S.print_communication_statistics() # random #proc: 0 1 2 3 4 5 6 7 reqs sent: 5 2 3 11 21 19 1 0 reqs rcvs: 10 10 9 5 1 11 9 2 - thefs: 1 0 0 0 0 0 0 0 + thefs: 0 0 1 0 0 0 0 0
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMPExample >>> S = RESetMPExample(maxl=Integer(6)) >>> S.run() 720*x^6 + 120*x^5 + 24*x^4 + 6*x^3 + 2*x^2 + x + 1 >>> S.print_communication_statistics() # random #proc: 0 1 2 3 4 5 6 7 reqs sent: 5 2 3 11 21 19 1 0 reqs rcvs: 10 10 9 5 1 11 9 2 - thefs: 1 0 0 0 0 0 0 0 + thefs: 0 0 1 0 0 0 0 0
- random_worker()[source]¶
Return a random worker.
OUTPUT: a worker for
selfchosen at randomEXAMPLES:
sage: from sage.parallel.map_reduce import RESetMPExample, RESetMapReduceWorker sage: from threading import Thread sage: EX = RESetMPExample(maxl=6) sage: EX.setup_workers(2) sage: EX.random_worker() <RESetMapReduceWorker...RESetMapReduceWorker-... initial...> sage: EX.random_worker() in EX._workers True
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMPExample, RESetMapReduceWorker >>> from threading import Thread >>> EX = RESetMPExample(maxl=Integer(6)) >>> EX.setup_workers(Integer(2)) >>> EX.random_worker() <RESetMapReduceWorker...RESetMapReduceWorker-... initial...> >>> EX.random_worker() in EX._workers True
Cleanup:
sage: del EX._results, EX._active_tasks, EX._done, EX._workers
>>> from sage.all import * >>> del EX._results, EX._active_tasks, EX._done, EX._workers
- reduce_function(a, b)[source]¶
Return the reducer function for
self.INPUT:
a,b– two values to be reduced
OUTPUT: by default the sum of
aandbNote
This should be overloaded in applications.
EXAMPLES:
sage: from sage.parallel.map_reduce import RESetMapReduce sage: S = RESetMapReduce() sage: S.reduce_function(4, 3) 7 sage: S = RESetMapReduce(reduce_function=lambda x,y: x*y) sage: S.reduce_function(4, 3) 12
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMapReduce >>> S = RESetMapReduce() >>> S.reduce_function(Integer(4), Integer(3)) 7 >>> S = RESetMapReduce(reduce_function=lambda x,y: x*y) >>> S.reduce_function(Integer(4), Integer(3)) 12
- reduce_init()[source]¶
Return the initial element for a reduction.
Note
This should be overloaded in applications.
- roots()[source]¶
Return the roots of
self.OUTPUT: an iterable of nodes
Note
This should be overloaded in applications.
EXAMPLES:
sage: from sage.parallel.map_reduce import RESetMapReduce sage: S = RESetMapReduce(42) sage: S.roots() 42
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMapReduce >>> S = RESetMapReduce(Integer(42)) >>> S.roots() 42
- run(max_proc=None, reduce_locally=True, timeout=None, profile=None)[source]¶
Run the computations.
INPUT:
max_proc– (integer, default:None) if given, the maximum number of worker processors to use. The actual number is also bounded by the value of the environment variableSAGE_NUM_THREADS(the number of cores by default).reduce_locally– seeRESetMapReduceWorker(default:True)timeout– a timeout on the computation (default:None)profile– directory/filename prefix for profiling, orNonefor no profiling (default:None)
OUTPUT:
The result of the map/reduce computation or an exception
AbortErrorif the computation was interrupted or timeout.EXAMPLES:
sage: from sage.parallel.map_reduce import RESetMPExample sage: EX = RESetMPExample(maxl = 8) sage: EX.run() 40320*x^8 + 5040*x^7 + 720*x^6 + 120*x^5 + 24*x^4 + 6*x^3 + 2*x^2 + x + 1
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMPExample >>> EX = RESetMPExample(maxl = Integer(8)) >>> EX.run() 40320*x^8 + 5040*x^7 + 720*x^6 + 120*x^5 + 24*x^4 + 6*x^3 + 2*x^2 + x + 1
Here is an example or how to deal with timeout:
sage: from sage.parallel.map_reduce import AbortError sage: EX = RESetMPExample(maxl = 100) sage: try: ....: res = EX.run(timeout=float(0.01)) ....: except AbortError: ....: print("Computation timeout") ....: else: ....: print("Computation normally finished") ....: res Computation timeout
>>> from sage.all import * >>> from sage.parallel.map_reduce import AbortError >>> EX = RESetMPExample(maxl = Integer(100)) >>> try: ... res = EX.run(timeout=float(RealNumber('0.01'))) ... except AbortError: ... print("Computation timeout") ... else: ... print("Computation normally finished") ... res Computation timeout
The following should not timeout even on a very slow machine:
sage: from sage.parallel.map_reduce import AbortError sage: EX = RESetMPExample(maxl = 8) sage: try: ....: res = EX.run(timeout=60) ....: except AbortError: ....: print("Computation Timeout") ....: else: ....: print("Computation normally finished") ....: res Computation normally finished 40320*x^8 + 5040*x^7 + 720*x^6 + 120*x^5 + 24*x^4 + 6*x^3 + 2*x^2 + x + 1
>>> from sage.all import * >>> from sage.parallel.map_reduce import AbortError >>> EX = RESetMPExample(maxl = Integer(8)) >>> try: ... res = EX.run(timeout=Integer(60)) ... except AbortError: ... print("Computation Timeout") ... else: ... print("Computation normally finished") ... res Computation normally finished 40320*x^8 + 5040*x^7 + 720*x^6 + 120*x^5 + 24*x^4 + 6*x^3 + 2*x^2 + x + 1
- run_serial()[source]¶
Run the computation serially (mostly for tests).
EXAMPLES:
sage: from sage.parallel.map_reduce import RESetMPExample sage: EX = RESetMPExample(maxl = 4) sage: EX.run_serial() 24*x^4 + 6*x^3 + 2*x^2 + x + 1
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMPExample >>> EX = RESetMPExample(maxl = Integer(4)) >>> EX.run_serial() 24*x^4 + 6*x^3 + 2*x^2 + x + 1
- setup_workers(max_proc=None, reduce_locally=True)[source]¶
Setup the communication channels.
INPUT:
max_proc– integer; an upper bound on the number of worker processesreduce_locally– whether the workers should reduce locally their work or sends results to the master as soon as possible. SeeRESetMapReduceWorkerfor details.
- start_workers()[source]¶
Launch the workers.
The workers should have been created using
setup_workers().
- class sage.parallel.map_reduce.RESetMapReduceWorker(mapred, iproc, reduce_locally)[source]¶
Bases:
ForkProcessWorker for generate-map-reduce.
This shouldn’t be called directly, but instead created by
RESetMapReduce.setup_workers().INPUT:
mapred– the instance ofRESetMapReducefor which this process is workingiproc– the id of this workerreduce_locally– when reducing the results. Three possible values are supported:True– means the reducing work is done all locally, the result is only sent back at the end of the work. This ensure the lowest level of communication.False– results are sent back after each finished branches, when the process is asking for more work.
- run()[source]¶
The main function executed by the worker.
Calls
run_myself()after possibly setting up parallel profiling.EXAMPLES:
sage: from sage.parallel.map_reduce import RESetMPExample, RESetMapReduceWorker sage: EX = RESetMPExample(maxl=6) sage: EX.setup_workers(1) sage: w = EX._workers[0] sage: w._todo.append(EX.roots()[0]) sage: w.run() sage: sleep(int(1)) sage: w._todo.append(None) sage: EX.get_results() 720*x^6 + 120*x^5 + 24*x^4 + 6*x^3 + 2*x^2 + x + 1
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMPExample, RESetMapReduceWorker >>> EX = RESetMPExample(maxl=Integer(6)) >>> EX.setup_workers(Integer(1)) >>> w = EX._workers[Integer(0)] >>> w._todo.append(EX.roots()[Integer(0)]) >>> w.run() >>> sleep(int(Integer(1))) >>> w._todo.append(None) >>> EX.get_results() 720*x^6 + 120*x^5 + 24*x^4 + 6*x^3 + 2*x^2 + x + 1
Cleanups:
sage: del EX._results, EX._active_tasks, EX._done, EX._workers
>>> from sage.all import * >>> del EX._results, EX._active_tasks, EX._done, EX._workers
- run_myself()[source]¶
The main function executed by the worker.
EXAMPLES:
sage: from sage.parallel.map_reduce import RESetMPExample, RESetMapReduceWorker sage: EX = RESetMPExample(maxl=6) sage: EX.setup_workers(1) sage: w = EX._workers[0] sage: w._todo.append(EX.roots()[0]) sage: w.run_myself() sage: sleep(int(1)) sage: w._todo.append(None) sage: EX.get_results() 720*x^6 + 120*x^5 + 24*x^4 + 6*x^3 + 2*x^2 + x + 1
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMPExample, RESetMapReduceWorker >>> EX = RESetMPExample(maxl=Integer(6)) >>> EX.setup_workers(Integer(1)) >>> w = EX._workers[Integer(0)] >>> w._todo.append(EX.roots()[Integer(0)]) >>> w.run_myself() >>> sleep(int(Integer(1))) >>> w._todo.append(None) >>> EX.get_results() 720*x^6 + 120*x^5 + 24*x^4 + 6*x^3 + 2*x^2 + x + 1
Cleanups:
sage: del EX._results, EX._active_tasks, EX._done, EX._workers
>>> from sage.all import * >>> del EX._results, EX._active_tasks, EX._done, EX._workers
- send_partial_result()[source]¶
Send results to the MapReduce process.
Send the result stored in
self._resto the master and reinitialize it tomaster.reduce_init.EXAMPLES:
sage: from sage.parallel.map_reduce import RESetMPExample, RESetMapReduceWorker sage: EX = RESetMPExample(maxl=4) sage: EX.setup_workers(1) sage: w = EX._workers[0] sage: w._res = 4 sage: w.send_partial_result() sage: w._res 0 sage: EX._results.get() 4
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMPExample, RESetMapReduceWorker >>> EX = RESetMPExample(maxl=Integer(4)) >>> EX.setup_workers(Integer(1)) >>> w = EX._workers[Integer(0)] >>> w._res = Integer(4) >>> w.send_partial_result() >>> w._res 0 >>> EX._results.get() 4
- steal()[source]¶
Steal some node from another worker.
OUTPUT: a node stolen from another worker chosen at random
EXAMPLES:
sage: from sage.parallel.map_reduce import RESetMPExample, RESetMapReduceWorker sage: from threading import Thread sage: EX = RESetMPExample(maxl=6) sage: EX.setup_workers(2) sage: # known bug (Issue #27537) sage: w0, w1 = EX._workers sage: w0._todo.append(42) sage: thief0 = Thread(target = w0._thief, name='Thief') sage: thief0.start() sage: w1.steal() 42 sage: w0._todo deque([])
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMPExample, RESetMapReduceWorker >>> from threading import Thread >>> EX = RESetMPExample(maxl=Integer(6)) >>> EX.setup_workers(Integer(2)) >>> # known bug (Issue #27537) >>> w0, w1 = EX._workers >>> w0._todo.append(Integer(42)) >>> thief0 = Thread(target = w0._thief, name='Thief') >>> thief0.start() >>> w1.steal() 42 >>> w0._todo deque([])
- walk_branch_locally(node)[source]¶
Work locally.
Performs the map/reduce computation on the subtrees rooted at
node.INPUT:
node– the root of the subtree explored
OUTPUT: nothing, the result are stored in
self._resThis is where the actual work is performed.
EXAMPLES:
sage: from sage.parallel.map_reduce import RESetMPExample, RESetMapReduceWorker sage: EX = RESetMPExample(maxl=4) sage: w = RESetMapReduceWorker(EX, 0, True) sage: def sync(): pass sage: w.synchronize = sync sage: w._res = 0 sage: w.walk_branch_locally([]) sage: w._res x^4 + x^3 + x^2 + x + 1 sage: w.walk_branch_locally(w._todo.pop()) sage: w._res 2*x^4 + x^3 + x^2 + x + 1 sage: while True: w.walk_branch_locally(w._todo.pop()) Traceback (most recent call last): ... IndexError: pop from an empty deque sage: w._res 24*x^4 + 6*x^3 + 2*x^2 + x + 1
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetMPExample, RESetMapReduceWorker >>> EX = RESetMPExample(maxl=Integer(4)) >>> w = RESetMapReduceWorker(EX, Integer(0), True) >>> def sync(): pass >>> w.synchronize = sync >>> w._res = Integer(0) >>> w.walk_branch_locally([]) >>> w._res x^4 + x^3 + x^2 + x + 1 >>> w.walk_branch_locally(w._todo.pop()) >>> w._res 2*x^4 + x^3 + x^2 + x + 1 >>> while True: w.walk_branch_locally(w._todo.pop()) Traceback (most recent call last): ... IndexError: pop from an empty deque >>> w._res 24*x^4 + 6*x^3 + 2*x^2 + x + 1
- class sage.parallel.map_reduce.RESetParallelIterator(roots=None, children=None, post_process=None, map_function=None, reduce_function=None, reduce_init=None, forest=None)[source]¶
Bases:
RESetMapReduceA parallel iterator for recursively enumerated sets.
This demonstrates how to use
RESetMapReduceto get an iterator on a recursively enumerated set for which the computations are done in parallel.EXAMPLES:
sage: from sage.parallel.map_reduce import RESetParallelIterator sage: S = RESetParallelIterator([[]], ....: lambda l: [l + [0], l + [1]] if len(l) < 15 else []) sage: sum(1 for _ in S) 65535
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetParallelIterator >>> S = RESetParallelIterator([[]], ... lambda l: [l + [Integer(0)], l + [Integer(1)]] if len(l) < Integer(15) else []) >>> sum(Integer(1) for _ in S) 65535
- map_function(z)[source]¶
Return a singleton tuple.
INPUT:
z– a node
OUTPUT:
The singleton
(z, ).EXAMPLES:
sage: from sage.parallel.map_reduce import RESetParallelIterator sage: S = RESetParallelIterator( [[]], ....: lambda l: [l + [0], l + [1]] if len(l) < 15 else []) sage: S.map_function([1, 0]) ([1, 0],)
>>> from sage.all import * >>> from sage.parallel.map_reduce import RESetParallelIterator >>> S = RESetParallelIterator( [[]], ... lambda l: [l + [Integer(0)], l + [Integer(1)]] if len(l) < Integer(15) else []) >>> S.map_function([Integer(1), Integer(0)]) ([1, 0],)
- reduce_init¶
alias of
tuple
- sage.parallel.map_reduce.proc_number(max_proc=None)[source]¶
Return the number of processes to use.
INPUT:
max_proc– an upper bound on the number of processes orNone
EXAMPLES:
sage: from sage.parallel.map_reduce import proc_number sage: proc_number() # random 8 sage: proc_number(max_proc=1) 1 sage: proc_number(max_proc=2) in (1, 2) True
>>> from sage.all import * >>> from sage.parallel.map_reduce import proc_number >>> proc_number() # random 8 >>> proc_number(max_proc=Integer(1)) 1 >>> proc_number(max_proc=Integer(2)) in (Integer(1), Integer(2)) True